How to Check What Googlebot Actually Sees (Step-by-Step)
Your page renders perfectly in Chrome. Googlebot gets 3KB of HTML and nothing else. Here's how to verify what bots actually receive — and why the difference kills your rankings.
We see this all the time:
3 KB
What Googlebot receives
0 words
Visible content for bots
180 KB
What Chrome renders
If you don't inspect the raw HTML response Googlebot receives, you are guessing. And guessing is why pages get crawled and never indexed.
Google indexes HTML. Not your app. Not your JavaScript. Just HTML.
On This Page
The Gap Nobody Talks About
Modern JS apps ship a tiny HTML shell and rely on client-side rendering. The browser downloads your JavaScript, executes it, hydrates the DOM, and renders content. Works great for humans.
Googlebot does something different. It requests your HTML, gets that tiny shell, and sometimes queues your page for JavaScript rendering later. Sometimes hours later. Sometimes never.
That gap — between what Chrome shows and what the initial HTTP response contains — is why your page gets crawled and never indexed. If your HTML response is empty, your page doesn't exist to Google. Everything else is noise.
What's Actually Happening
Most React / Vite / SPA apps return something like this to every request — including Googlebot:
<!DOCTYPE html>
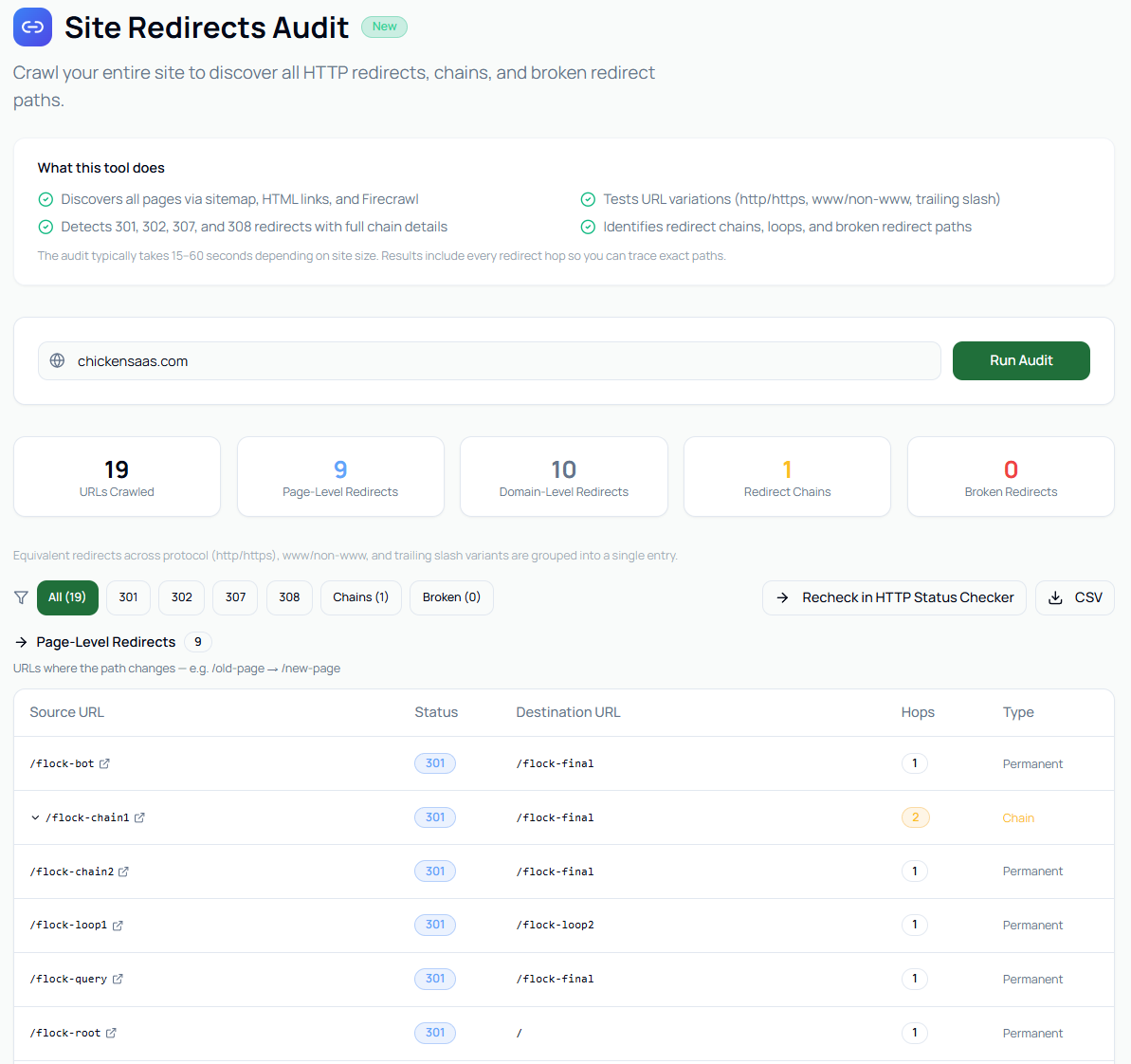
<html>
<head><title>My App</title></head>
<body>
<div id="root"></div>
<script type="module" src="/assets/index-abc123.js"></script>
</body>
</html>That's it. 2–8KB of HTML. One empty div. Several script tags. No real content.
What the Browser Does
- Downloads the JavaScript bundle
- Executes it
- Hydrates the DOM
- Renders your content
Result: Full page, all content visible
What Googlebot Does
- Requests the HTML
- Sometimes queues JS rendering
- Often indexes the initial response
- Moves on
Result: Empty shell, nothing to index
Your own snapshot system literally waits for DOM stability, router readiness, and hydration before extracting content. Googlebot does not wait that long.
Step-by-Step: Check What Googlebot Actually Sees
Fetch the Raw HTML as Googlebot
Make a request using a Googlebot user agent. This is the single most important diagnostic step — it shows you exactly what Google's crawler receives.
curl -s -A "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" \
https://yoursite.com | head -100What you're looking for:
- HTML size — how many bytes came back
- Visible text — actual words, not script tags
- Real markup — h1, paragraphs, links, not just a root div
Hard signals:
If you see mostly script tags, the page is not indexable. Full stop.
Fetch the Same Page as a Browser
Now request the same URL with a normal browser user agent. This gives you the baseline for comparison.
curl -s -A "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36" \
https://yoursite.com | wc -cCompare these numbers:
Metric
Browser
Googlebot
If those differ significantly, you have a rendering gap. This breaks in production constantly.
Diff the Actual Content
Don't just compare sizes — inspect the content itself. Run a direct comparison:
- Is your main text present in the raw HTML?
- Are headings (h1, h2) visible?
- Are internal links crawlable?
Example failure we see constantly:
Browser HTML
220KB, full pricing page with tables, CTAs, and FAQ
Googlebot HTML
4KB, empty div, three script tags
Result: Google indexes nothing. The page is invisible.
Or use our HTTP Bot Comparison Tool to do this automatically — it fetches as multiple user agents and shows you the diff side by side.
Verify Response Behavior (Not Just Content)
Content doesn't matter if the request itself fails. Check the response before inspecting the body:
curl -sI -A "Mozilla/5.0 (compatible; Googlebot/2.1)" https://yoursite.com- Status must be 200
- No redirect loops
- No 403 / blocked responses
- No host mismatch issues
Real infrastructure failures we see:
- Cloudflare returns 5xx → bot gets an error page instead of content
- TLS handshake fails → bot gets nothing at all
- Wrong host header → origin server rejects the request
- CDN cache miss → origin timeout, bot gets stale or empty response
If the request fails, content doesn't matter. Check the response first.
Our HTTP Debug Tool checks all of these automatically — status codes, redirects, headers, TLS, and response differences between user agents.
Validate Minimum Content Signals
Use hard thresholds. These aren't "nice-to-have checks" — they map directly to indexing failures:
Visible text
> 200 characters
HTML size
> 15KB
Title tag
Present and populated
H1 tag
Present and populated
Our Guard system already encodes these exact checks:
- Blank page: visible text < 200 characters
- Script shell: HTML present but contains no real content
- Partial hydration: some content present but critical sections missing
What Most Guides Get Wrong
Most SEO guides operate on three dangerous assumptions:
"Google will render your page"
Rendering is delayed, inconsistent, and never guaranteed. You can't depend on it.
"JavaScript execution is reliable"
Bundle failures, hydration crashes, and API timeouts silently kill rendering for bots.
"GSC reflects reality"
The URL Inspection tool renders with a full Chrome instance. Real Googlebot crawling is far more constrained.
What they ignore entirely:
- Initial HTML size (the single most important signal)
- Missing content in the first HTTP response
- Infrastructure failures — TLS, CDN, headers
Google does not guarantee rendering. If your HTML is empty, your page is invisible. That's not an edge case — it's the default for every React, Vue, and Angular SPA.
What We See in Production
These aren't theoretical. They're common, repeatable failure patterns we diagnose on real sites every week.
Empty HTML Shell
HTML: 3KB. Content: none. Just script tags and an empty root div.
Result: Crawled, never indexed. Google has nothing to work with.
Hydration Crash
JavaScript throws an error during hydration. The DOM never renders. This shows up intermittently — sometimes the page works, sometimes it doesn't.
Result: Intermittent indexing, unstable rankings, impossible to debug without raw HTML inspection.
CDN / Origin Blocking
The page works perfectly in a browser. But the bot gets a 403 or 5xx from Cloudflare, Vercel, or your WAF. The origin rejects the request based on user-agent, IP range, or rate limiting.
Result: Google drops the page entirely. No indexing, no ranking.
Deep Link Failure
/pricing works in the browser because client-side routing handles it. But when Googlebot requests /pricing directly, the server returns 404 because there's no server-side route configured.
Result: Key revenue pages never indexed. Your SPA fallback serves humans but not bots.
Content Mismatch
Browser sees 180KB of HTML with 1,500 words. Bot sees 6KB with approximately zero words. Same URL, completely different experience.
Result: Page exists in the index but Google has nothing meaningful to rank it for.
Solutions Compared: Prerender vs SSR vs Edge
Prerendering
Static HTML generated ahead of time. Works for fixed routes.
Breaks when: Pages are dynamic, routes scale beyond a few hundred, or content changes frequently.
Server-Side Rendering (SSR)
Server returns full HTML per request. Works reliably.
Costs: Complexity, infrastructure overhead, and it's a hard retrofit for existing SPAs. You're effectively rewriting your rendering pipeline.
Edge Proxy (DataJelly Approach)
Detect bots at the edge. Serve HTML snapshots to search bots. Serve structured Markdown to AI crawlers. Serve your app normally to humans.
Search bots → fully rendered HTML snapshot
AI crawlers → structured Markdown
Humans → your SPA, unchanged
No app rewrite. No infra overhead. Fixes the empty HTML problem immediately.
Practical Checklist
Run this every time you deploy, launch a new page, or change your rendering setup:
Fetch as Googlebot — inspect raw HTML
Check HTML size — target > 20KB
Verify visible text — target > 200 characters
Confirm title and H1 are present
Compare bot vs browser output
Check HTTP status — must be 200
Test deep links directly (not via nav)
Verify no CDN or WAF blocking
Inspect raw HTML — not the rendered DOM
If any of these fail, indexing will fail.
Skip the Terminal — Use Our HTTP Bot Comparison Tool
The curl workflow above works, but it's manual and tedious. We built the HTTP Bot Comparison Tool to automate the entire process — and it checks bot categories that curl can't easily simulate.
Enter any URL and the tool runs two parallel fetches: a Raw HTTP request (what bots get on the first hit) and a JS Rendered request (what a headless browser produces after executing JavaScript). You get a side-by-side comparison instantly.
What it checks across bot types
Search Bots
Googlebot, Bingbot, Yandex
- • HTML size & word count
- • Title & meta description
- • Status code & redirects
- • Content gap (raw vs rendered)
AI Crawlers
ChatGPT, Claude, Perplexity
- • Markdown vs HTML format detection
- • Content structure quality
- • Word count & readability
- • Whether AI gets usable content
Social Bots
Facebook, Twitter, LinkedIn
- • Open Graph tags (og:title, og:image)
- • Twitter Card meta
- • Social preview accuracy
- • Missing or generic metadata
What the results tell you
The tool shows two result sets — Raw HTTP and JS Rendered — with a comparison view that highlights the gap:
Raw HTTP Results
What bots receive on the first request — URL, status, user-agent, word count, HTML size, title, meta description, social card tags, and the actual HTML content. This is what you'd get from the curl commands above, but automated.
JS Rendered Results
What a headless browser produces after JavaScript execution and DOM hydration. This represents what your users see — and what you think Google sees.
Comparison View
Side-by-side diff showing word count difference (e.g., +3,301 / 526%), HTML size gap (e.g., 4.2KB → 21.6KB), format detection (AI Markdown vs HTML), and whether titles or social tags differ between raw and rendered responses.
Example from a real site we tested:
Raw HTTP
628 words
4.2 KB
JS Rendered
3,929 words
21.6 KB
Gap
+526%
content invisible to bots
That's 3,301 words of content that search bots and AI crawlers never see. The page looks perfect in Chrome — and is nearly empty to Googlebot.
Quick Test: Verify Your Site Right Now
Quick Test: What Do Bots Actually See?
Most people guess. Don't.
Run this test and look at the actual response your site returns to bots.
Fetch your page as Googlebot
Use your terminal:
curl -A "Googlebot" https://yourdomain.comLook for:
- Real visible text (not just
<div id="root">) - Meaningful content in the HTML
- Page size (should not be tiny)
Compare bot vs browser
Now test what a real browser gets:
curl -A "Mozilla/5.0" https://yourdomain.comIf these responses are different, Google is indexing a different page than your users see.
Stop guessing — measure it.
Real example: 253 words vs 13,547
We see this constantly. Here's a real example from production: Googlebot saw 253 words and 2 KB of HTML. A browser saw 13,547 words and 77.5 KB. Same URL — completely different content.
If your HTML doesn't contain the content, Google doesn't either.
Compare Googlebot vs browser on your site → HTTP Debug ToolCheck for common failure signals
We see this all the time in production:
- HTML under ~1KB → usually empty shell
- Visible text under ~200 characters → thin or missing content
- Missing <title> or <h1> → weak or broken page
- Large difference between bot vs browser HTML → rendering issue
Use the DataJelly Visibility Test (Recommended)
You can run this without touching curl. It shows you:
- Raw HTML returned to bots (Googlebot, Bing, GPTBot, etc.)
- Fully rendered browser version
- Side-by-side differences in word count, HTML size, links, and content
What this test tells you (no guessing)
After running this, you'll know:
- Whether your HTML is actually indexable
- Whether bots are seeing partial content
- Whether rendering is breaking in production
This is the difference between "I think SEO is set up" and "I know what Google is indexing."
If you don't understand why this happens, read: Why Google Can't See Your SPA
If this test fails
You have three real options:
SSR
Works if you can keep it stable in production
Prerendering
Breaks with dynamic content and scale
Edge Rendering
Reflects real production output without app changes
If you do nothing, you will not rank consistently. Learn how Edge Rendering works →
This issue doesn't show up in Lighthouse. It shows up in rankings.
See the gap for yourself
Our homepage visibility test compares what bots see vs what your users see. Takes under 60 seconds.
Run the Visibility Test(No signup required)