The Real Problem
Browser view
13,547
words rendered
GPTBot view
253
words in HTML
ChatGPT knows
Nothing
about your page
We see this constantly. A team ships a React or Vite app, gets it ranking in Google (sometimes), and then discovers that ChatGPT, Claude, and Perplexity have no idea the content exists.
The reason is straightforward: if your page ships less than ~10KB of meaningful HTML — or under ~200–300 words in the initial response — AI crawlers treat it as empty. They don't execute JavaScript. They don't wait for your API calls. They don't hydrate your components.
No content in HTML = zero visibility in AI.
What's Actually Happening (Technical Explanation)
AI crawlers — GPTBot (ChatGPT), ClaudeBot, PerplexityBot — fetch your HTML and extract text. That's it. They are fast HTTP clients, not browsers.
They do not reliably:
- Execute JavaScript
- Wait for hydration
- Resolve client-side routing
- Fetch async data after page load
What they actually process:
- Raw HTML response body
- Text nodes in
<body> - Headings (
h1–h6) - Links and metadata
If your response looks like this at request time:
<!DOCTYPE html>
<html>
<head><title>My App</title></head>
<body>
<div id="root"></div>
<script src="/assets/index-abc123.js"></script>
</body>
</html>Then the crawler sees ~0–50 words. No headings. No structure. No product info. No blog content. That page is discarded — or worse, it's ingested as "this site has nothing useful."
What this looks like in DataJelly Guard scans: HTML under 1–5KB, visible text under 200 characters, DOM dominated by <script> and <noscript> tags. This is the #1 pattern we flag on JavaScript apps.
Why Most Fixes Don't Work
The typical advice is "just add SSR." We hear this constantly, and it's not wrong — it's just incomplete. SSR can work, but it fails silently in production more often than people realize.
SSR looks great in development
In dev, your backend is local, your APIs respond in milliseconds, and everything renders perfectly. In production, you hit real-world conditions: slow third-party APIs, database connection limits, CDN caching rules that serve stale HTML, and deployment rollouts that temporarily break server rendering.
The "it works on my machine" problem
You can't test SSR by opening your browser. The browser executes JavaScript and fills in the gaps. To see what bots get, you need to curl the page — or use a tool that fetches raw HTML. If you're not doing that regularly, you have no idea whether SSR is actually producing complete output.
We see teams that "have SSR" but are still invisible to AI because their SSR returns partial content. The server renders the layout but not the data. Or the API times out and the server sends an empty shell anyway. Or a hydration error prevents the page from ever completing.
Bottom line: SSR is a valid approach, but it's not a guarantee. If you're not monitoring what bots actually receive in production, you don't know if it's working.
What Breaks in Production
These aren't edge cases. We see these every week across customer sites and in our own diagnostic scans:
JavaScript Shell Apps
The most common failure. React, Vue, Vite, and every SPA framework ships an HTML file with a <div id="root"> and one or more script tags. The entire page content is generated by JavaScript.
What the bot sees: 1–3KB of HTML, 0–50 words, zero useful content. This is the baseline for most Lovable, Bolt, Replit, and v0 apps.
SSR with API Timeouts
Your SSR setup calls an API to get page data. The API takes 3 seconds. Your SSR timeout is 2 seconds. The server gives up and sends whatever it has — usually a layout shell with placeholders.
What the bot sees: A fully rendered header and footer with "Loading..." or empty content areas in between.
Hydration Errors
The server renders HTML, but when the client hydrates, there's a mismatch. React throws an error and re-renders the entire page — but the bot already left with the broken version.
What the bot sees: Partial content, sometimes with duplicate elements or missing sections. Inconsistent across requests.
Cached Empty Shells
Your CDN or edge cache stores the first response it sees. If that first response was an empty shell (from a failed SSR pass, a cold start, or a deployment), every subsequent bot request gets the cached empty page.
What the bot sees: The same empty shell, potentially for hours or days, until the cache expires. This is the sneakiest failure because your site works fine in browsers.
What AI Crawlers Actually Process
When ChatGPT (via GPTBot) or Perplexity crawls your site, the content needs to meet a minimum bar to be useful. Here's what we've observed from production data:
| Signal | Problem Threshold | What It Means |
|---|---|---|
| HTML size | < 5–10KB | Almost certainly an empty JavaScript shell |
| Word count | < 200 words | Not enough content to be useful for retrieval |
| Headings | 0 headings | No content structure — AI can't segment the page |
| Bot vs browser gap | > 5x difference | Content exists but isn't in the HTML |
| Meta description | Missing or generic | AI can't summarize or contextualize the page |
AI crawlers also benefit significantly from structured content. If you can serve clean Markdown instead of noisy HTML, you reduce token usage by ~91% and make your content dramatically easier for AI systems to ingest, chunk, and cite.
This is why we built AI Markdown Snapshots — structured, token-efficient content delivered to AI crawlers at the edge, so they get exactly what they need without parsing through navigation, scripts, and layout noise.
The Fix
There are three real approaches. Two of them require you to change your app. One doesn't.
| Approach | Pros | Cons | AI-Ready? |
|---|---|---|---|
| SSR (Next.js, Remix) | Full control, works well when stable | Requires app rewrite, fails silently in production | Partial — HTML only, no Markdown |
| Build-time Prerendering | Simple for static content | Breaks with dynamic content, stale data, scale limits | Partial — HTML only, gets stale |
| Edge Rendering (Visibility Layer) | No code changes, reflects real production content | Requires a service like DataJelly | Yes — HTML + AI Markdown |
The edge rendering approach works by intercepting bot requests at the DNS level. When GPTBot, ClaudeBot, or Googlebot requests a page, they get fully rendered HTML (or structured Markdown for AI crawlers). When a real user visits, they get your normal JavaScript app. No code changes. No build pipeline modifications.
This is what DataJelly Edge does. Setup takes about 15 minutes — add a DNS record, wait for propagation, and bots immediately start receiving complete content.
Quick Test: Is ChatGPT Ignoring Your Content?
Don't take our word for it. Run this test and see what your site actually returns to AI crawlers:
Quick Test: What Do Bots Actually See?
Most people guess. Don't.
Run this test and look at the actual response your site returns to bots.
Fetch your page as Googlebot
Use your terminal:
curl -A "Googlebot" https://yourdomain.comLook for:
- Real visible text (not just
<div id="root">) - Meaningful content in the HTML
- Page size (should not be tiny)
Compare bot vs browser
Now test what a real browser gets:
curl -A "Mozilla/5.0" https://yourdomain.comIf these responses are different, Google is indexing a different page than your users see.
Stop guessing — measure it.
Real example: 253 words vs 13,547
We see this constantly. Here's a real example from production: Googlebot saw 253 words and 2 KB of HTML. A browser saw 13,547 words and 77.5 KB. Same URL — completely different content.
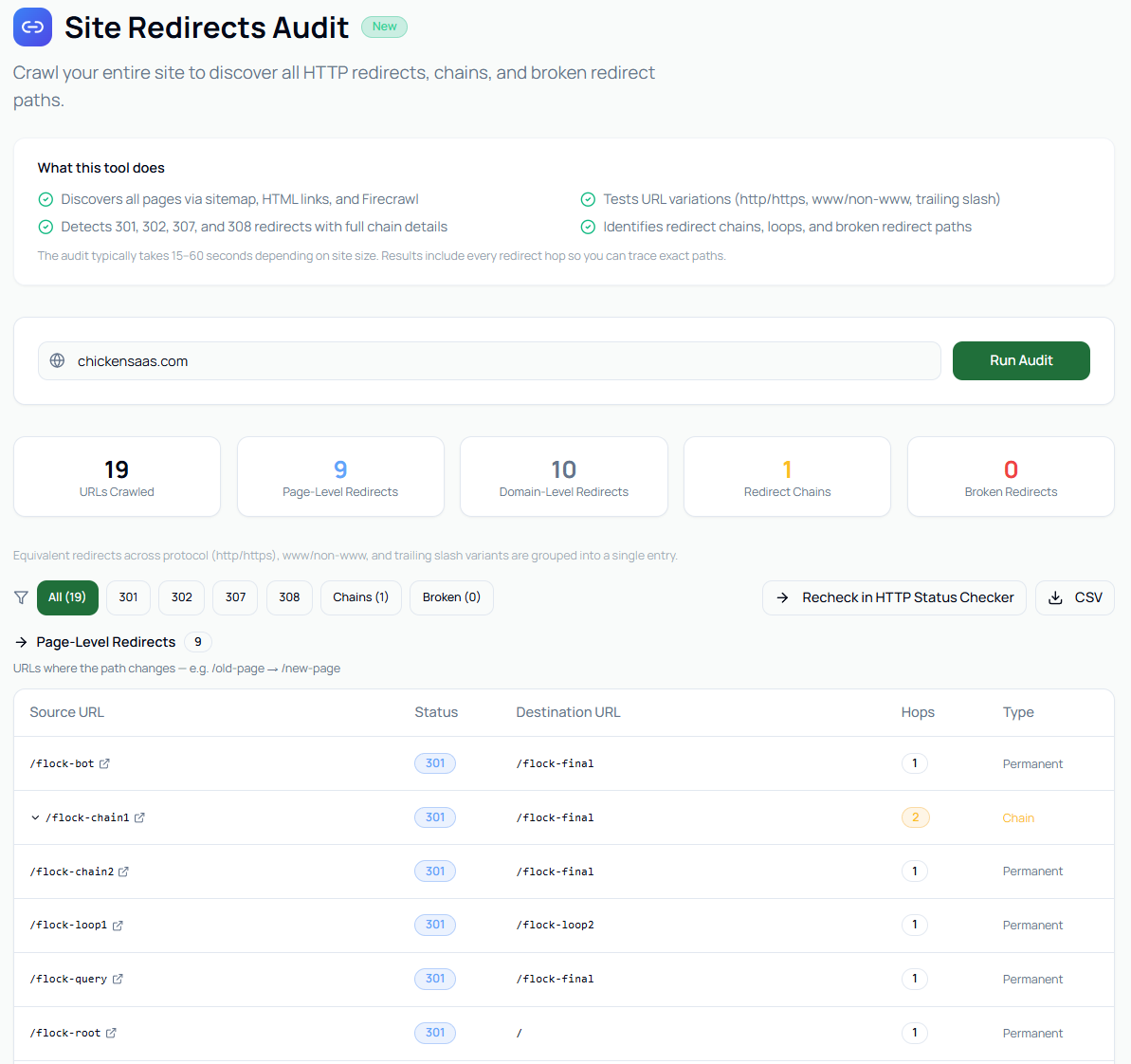
If your HTML doesn't contain the content, Google doesn't either.
Compare Googlebot vs browser on your site → HTTP Debug ToolCheck for common failure signals
We see this all the time in production:
- HTML under ~1KB → usually empty shell
- Visible text under ~200 characters → thin or missing content
- Missing <title> or <h1> → weak or broken page
- Large difference between bot vs browser HTML → rendering issue
Use the DataJelly Visibility Test (Recommended)
You can run this without touching curl. It shows you:
- Raw HTML returned to bots (Googlebot, Bing, GPTBot, etc.)
- Fully rendered browser version
- Side-by-side differences in word count, HTML size, links, and content
What this test tells you (no guessing)
After running this, you'll know:
- Whether your HTML is actually indexable
- Whether bots are seeing partial content
- Whether rendering is breaking in production
This is the difference between "I think SEO is set up" and "I know what Google is indexing."
If you don't understand why this happens, read: Why Google Can't See Your SPA
If this test fails
You have three real options:
SSR
Works if you can keep it stable in production
Prerendering
Breaks with dynamic content and scale
Edge Rendering
Reflects real production output without app changes
If you do nothing, you will not rank consistently. Learn how Edge Rendering works →
This issue doesn't show up in Lighthouse. It shows up in rankings.
Frequently Asked Questions
Ready to fix your AI visibility?
Find out what ChatGPT, Claude, and Perplexity actually see when they visit your site.